General Theory
In many instances, the final value returned by a regression may depend on the starting point of the regression. In most cases, the user gets around this by running multiple regressions at different starting points and with different learning rates. Colossus includes several functions built in that automate this process for several situations the user may find themselves in. This vignette will cover descriptions of several situations to use these distributed start functions and descriptions of the inputs for each function.
Common Convergence Issues
Large Multi-Dimensional Space
Generally speaking, the optimization methods used in Colossus and similar software are based on using derivatives to improve the log-likelihood or some measure of deviance. These methods search for an optimum, but it is not guaranteed to be a global optimum. The final solution may be dependent on the initial regression conditions. For a model with a small number of covariates or a well-understood relationship between covariate and event, the user may be able to start the regression near the global optimum. If the model is composed of dozens of covariates, this becomes less likely.
The solution an experienced user might come to is to try multiple starting points and see if they all converge to the same solution. Colossus tries to make this easier by automating the process. The user provides Colossus with an initial starting point to try, parameters controlling how many random points to try, and how to generate them. Currently, Colossus only supports uniformly generated points with user-provided minimum and maximum values. The log-linear terms generally have a different range of acceptable values than the linear terms, so different minimum and maximum values can be given for log-linear terms than the other options.
There is one special case of large multi-dimensional spaces that has been given a separate function. This would be general multi-term models. This case assumes that the model can be split into multiple independent terms that can be solved separately. Colossus automates splitting the model into a simplified form, searching for a solution, substituting the final solution for the simplified model into the full model, and then searching for a solution to the full model near the solution to the simplified model. A common example would be solving for the background model (simplified model) and then adding additional risk factors to make a full model.
Infeasible Parameter Spaces
The risks calculated for Cox Proportional Hazards and Poisson model regressions are generally assumed to be strictly positive values. The use of log-likelihoods as a scoring metric would not be possible without this assumption. However, it is likely that, during a regression, the risk may be calculated with a set of parameters that would give a negative probability of an event. To illustrate consider the following Poisson model.
The number of events predicted for an interval is proportional to the risk and number of person-years. The exponential term is always strictly positive, but if is negative the risk and number of events can also be negative. Suppose we have several ranges of parameters that give negative event rates such that we get the following plot of score by parameter values:
x <- c(
-2.0, -1.667, -1.333, -1.0, -0.667, -0.333, 0.0, -2.0, -1.667, -1.333, -1.0, -0.667,
-0.333, 0.0, -2.0, -1.667, -1.333, -1.0, -0.667, -0.333, 0.0, -2.0, -1.667, -1.333,
-1.0, -0.667, -0.333, 0.0, -2.333, -2.0, -1.667, -1.333, -0.667, -0.333, 0.0, -3.0,
-2.667, -2.333, -2.0, -1.667, -0.333, 0.0, -3.0, -2.667, -2.333, -2.0, 0.0, -3.0,
-2.667, -2.333, -2.0, -1.667, -0.333, 0.0, -3.0, -2.667, -2.333, -2.0, -1.667,
-1.333, -0.667, -0.333, 0.0, -3.0, -2.667, -2.333, -2.0, -1.667, -1.333, -1.0,
-0.667, -0.333, 0.0
)
y <- c(
-3.0, -3.0, -3.0, -3.0, -3.0, -3.0, -3.0, -2.667, -2.667, -2.667, -2.667, -2.667,
-2.667, -2.667, -2.333, -2.333, -2.333, -2.333, -2.333, -2.333, -2.333, -2.0, -2.0,
-2.0, -2.0, -2.0, -2.0, -2.0, -1.667, -1.667, -1.667, -1.667, -1.667, -1.667, -1.667,
-1.333, -1.333, -1.333, -1.333, -1.333, -1.333, -1.333, -1.0, -1.0, -1.0, -1.0,
-1.0, -0.667, -0.667, -0.667, -0.667, -0.667, -0.667, -0.667, -0.333, -0.333,
-0.333, -0.333, -0.333, -0.333, -0.333, -0.333, -0.333, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0
)
c <- c(
3.0, 3.85, 4.46, 4.896, 5.209, 5.433, 5.594, 2.278, 3.333, 4.089, 4.631, 5.019, 5.297,
5.496, 1.455, 2.744, 3.667, 4.328, 4.802, 5.142, 5.385, 0.563, 2.105, 3.209, 4.0, 4.567,
4.973, 5.264, 3.674, 2.754, 1.47, 2.754, 4.333, 4.806, 5.144, 5.315, 5.045, 4.667, 4.139,
3.403, 4.667, 5.045, 5.632, 5.487, 5.283, 5.0, 5.0, 5.824, 5.755, 5.658, 5.522, 5.333,
4.702, 5.07, 5.937, 5.912, 5.877, 5.829, 5.761, 5.667, 5.351, 5.094, 5.351, 6.0, 6.0,
6.0, 6.0, 6.0, 6.0, 6.0, 6.0, 6.0, 6.0
)
dft <- data.table("x" = x, "y" = y, "c" = c)
g <- ggplot() +
geom_point(data = dft, aes(
x = .data$x, y = .data$y,
color = .data$c
), size = 4) +
scale_fill_continuous(guide = guide_colourbar(title = "-2*Log-Likelihood")) +
xlab("Linear Parameter") +
ylab("Log-Linear Parameter")
g + scale_colour_viridis_c()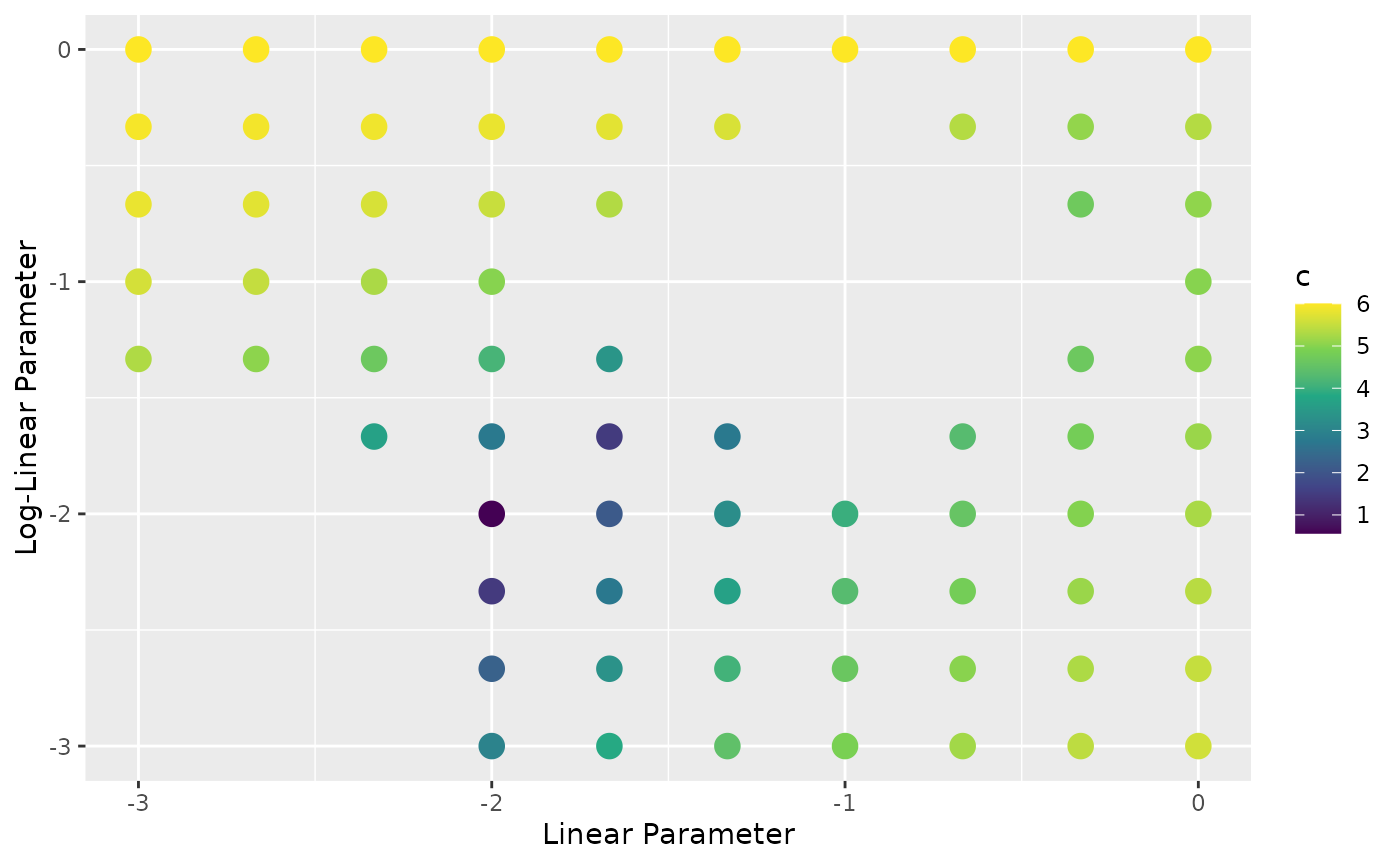
-2*Log-Likelihood With Infeasible Points Removed
In this plot, the ranges of missing data show infeasible points. The goal of regression is to reduce the Log-Likelihood close to 0, so the solution would be near the point . If the regression started near the origin it may end up in either of the infeasible ranges. The user might catch this issue beforehand and start the regression carefully to avoid the infeasible ranges. Colossus can automate this process by sampling across a range of possible values and automatically removing infeasible points.
Provided Functions
| Function | Description |
|---|---|
| RunCoxRegression_Guesses | Repeats Cox Proportional Hazards regression at random points, then runs the best for more iterations |
| RunCoxRegression_Tier_Guesses | Repeats Cox Proportional Hazards regression for a subset of terms, then repeats with the full model |
| RunPoissonRegression_Guesses | Repeats Poisson model regression at random points, then runs the best for more iterations |
| RunPoissonRegression_Tier_Guesses | Repeats Poisson model regression for a subset of terms, then repeats with full model |
All of these use the same parameters the respective Cox Proportional Hazards and Poisson model regression functions use, with the addition of a control term listing options for the guessing process.
| Option | Description |
|---|---|
| maxiter | Iterations run for every random starting point |
| guesses | Number of starting points to test |
| guesses_start | Number of starting points tested for Tiered or Strata First regressions |
| guess_constant | Binary values to denote if any parameter values should not be randomized |
| exp_min | minimum exponential parameter change |
| exp_max | maximum exponential parameter change |
| intercept_min | minimum intercept parameter change |
| intercept_max | maximum intercept parameter change |
| lin_min | minimum linear slope parameter change |
| lin_max | maximum linear slope parameter change |
| exp_slope_min | minimum linear-exponential, exponential slope parameter change |
| exp_slope_max | maximum linear-exponential, exponential slope parameter change |
| strata | True/False if stratification is used |
| term_initial | List of term numbers to run first if Tiered guessing is used |
| rmin | list of minimum changes for each parameter |
| rmax | list of maximum change for each parameter |
| verbose | integer valued 0-4 controlling what information is printed to the terminal. Each level includes the lower levels. 0: silent, 1: errors printed, 2: warnings printed, 3: notes printed, 4: debug information printed. Errors are situations that stop the regression, warnings are situations that assume default values that the user might not have intended, notes provide information on regression progress, and debug prints out C++ progress and intermediate results. The default level is 2 and True/False is converted to 3/0. |
If “rmin” and “rmax” are not used, then the remaining “_min” and “_max” values are used instead. The “guess_constant” values take priority over the “rmin” and “rmax” values.